

Skalenniveaus
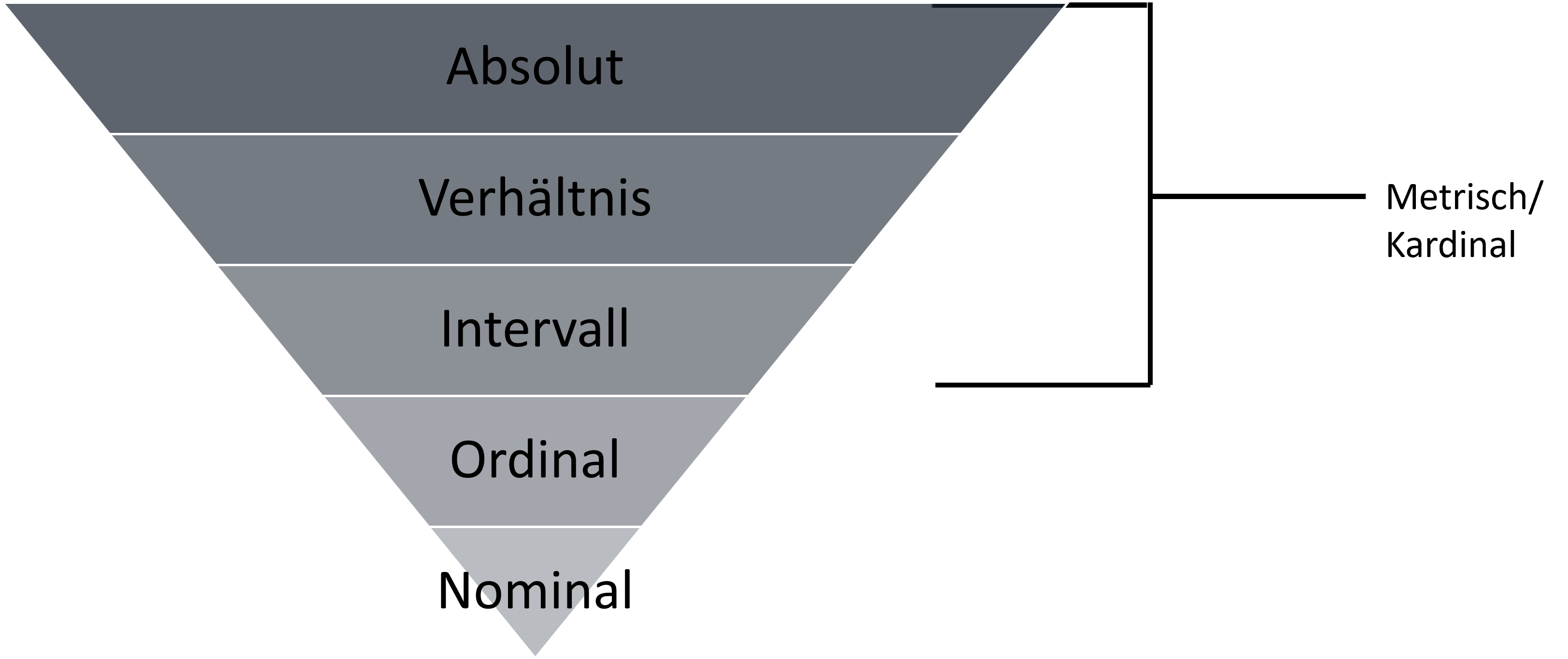
Eins der wichtigsten Kriterien im Datenanalyseprozess ist das Festlegen des richtiges Skalenniveaus. Für die Datenaufbereitung, Datenvisualisierung, deskriptive Statistik und die Wahl des richtigen Hypothesentests ist es daher von entscheidender Bedeutung. Wir unterscheiden in der Theorie zwischen 5 Niveaus.
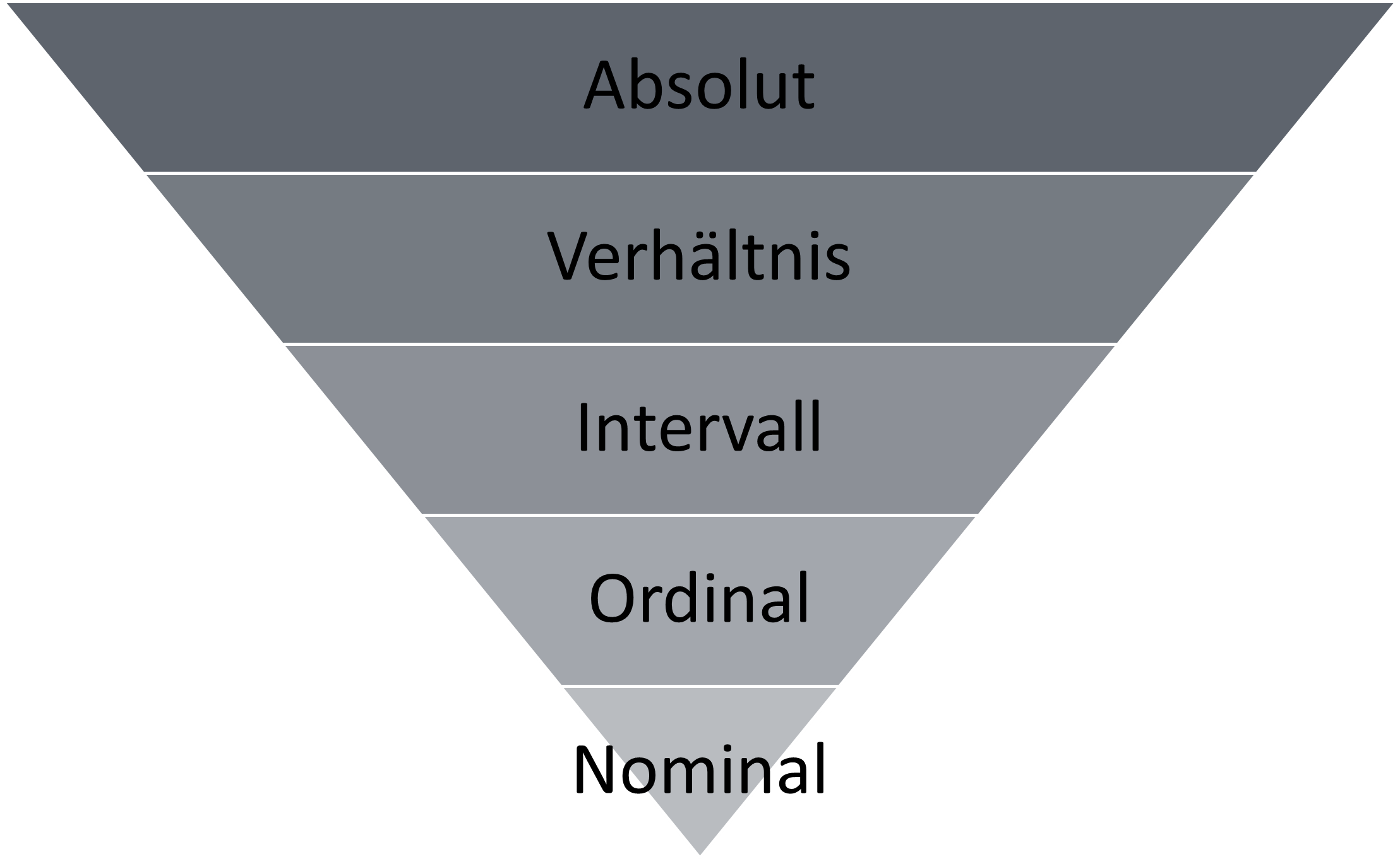
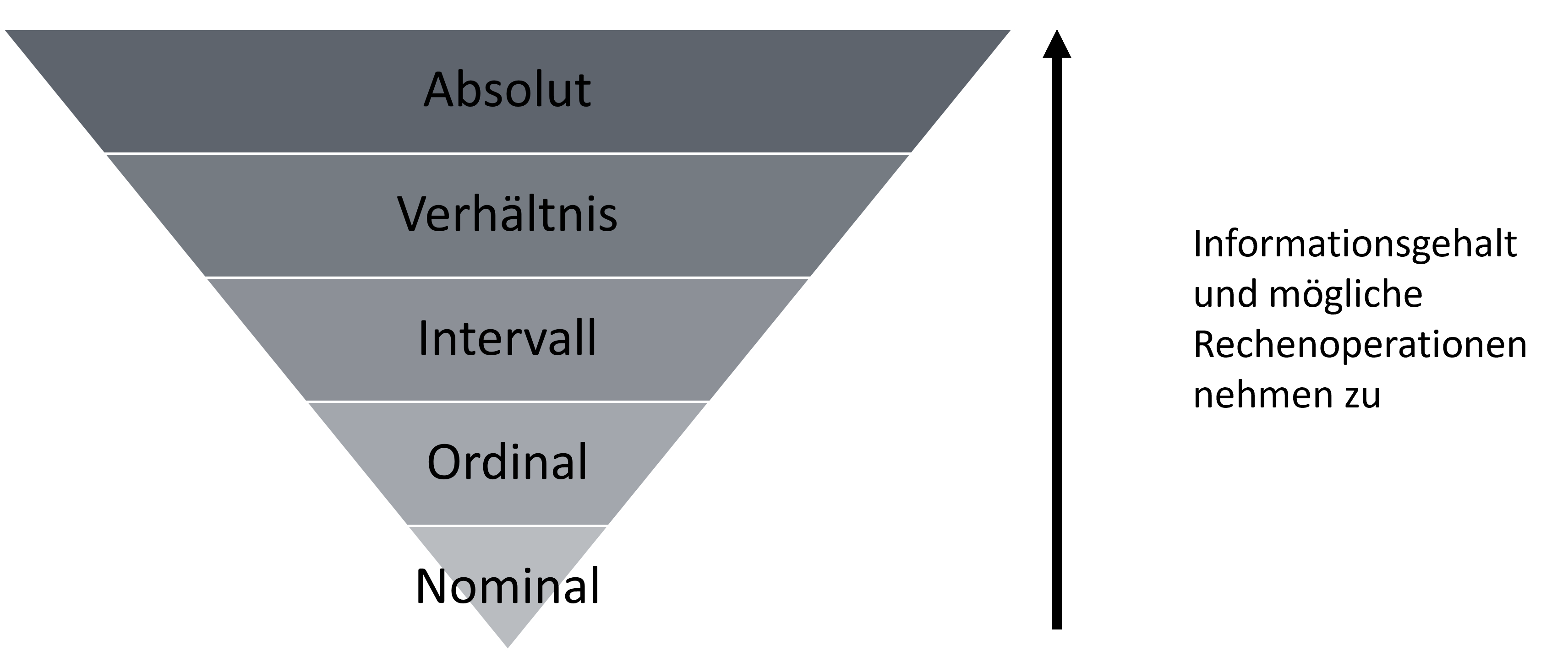
Den Skalenniveaus liegt dabei ein verschiedener Informationsgehalt zugrunde.
einfache Beispiele für nominale-, ordinale-, intervallskalierte-, verhältnisskalierte- und absolutskalierte Daten sind:
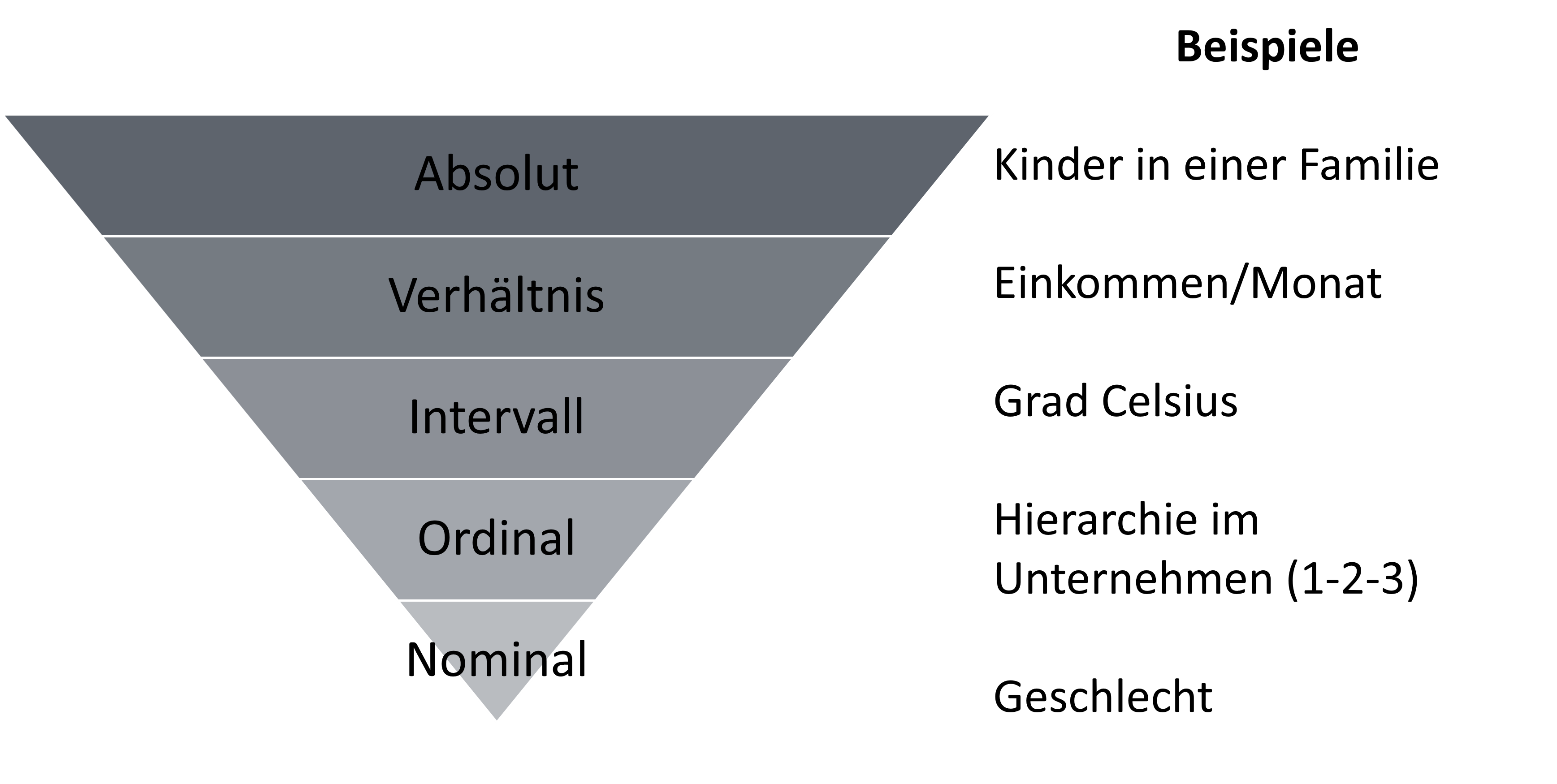
Nominale Daten sind einfache Kategorien, wie das Geschlecht (m,w,d).
Ordinale Daten sind Kategorien mit Rangfolge, wie die Hierarchie im Unternehmen oder ungleichgroße Zeiträume (z.B. Wie oft machst du Sport? Einmal am Tag – Einmal die Woche – Mehrfach die Woche - Einmal im Monat).
Intervall Daten haben dagegen gleichgroße Abstände, z.B. Likert Skalen (sehr gut – gut – teils/teils – schlecht – sehr schlecht).
Verhältnis Daten haben, wie der Begriff bereits vermuten lässt, funktionierende Relationen, wie das Alter. Ein 80-Jähriger ist genau doppelt so alt, wie eine 40-Jährige. Hingegen sind -5°C nicht doppelt so kalt wie 5°C. Aufgrund des fehlenden natürlichen Nullpunkts bei Grad Celsius funktioniert diese Logik hier nicht mehr. Ähnlich sieht es bei ordinalen Daten aus. Die Schulnote 4 ist nicht doppelt so schlecht wie die Note 2. Aufgrund unterschiedlicher Abstände zwischen den Noten können keine Relationen hergestellt werden.
Absolute Daten beschreiben natürliche, nicht teilbare Einheiten. Zum Beispiel die Kinder einer Familie.
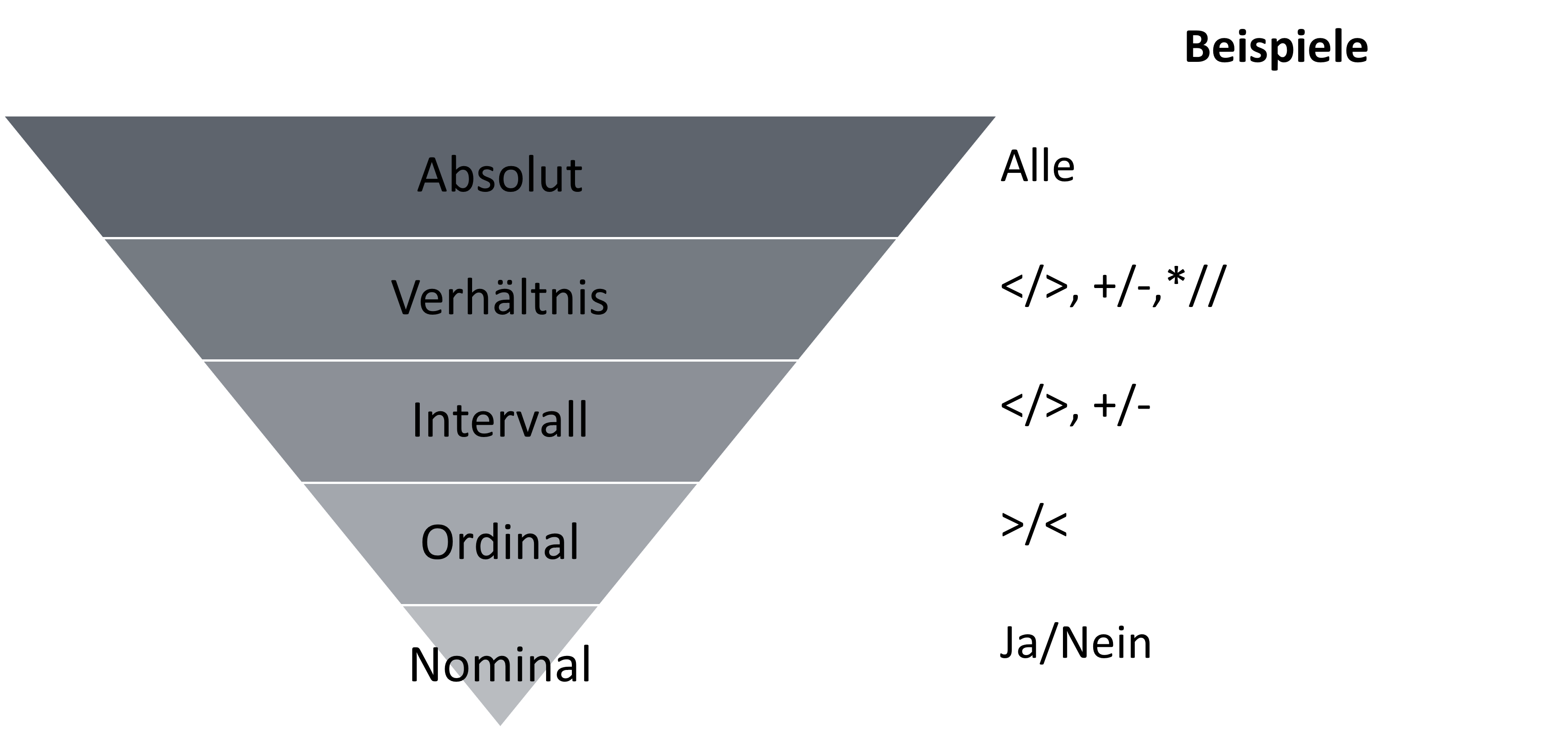
Du kannst also je nach Datentyp verschiedene Operationen durchführen oder eben nicht. Bei einer Variable, die das Geschlecht misst (1=weiblich, 2=männlich, 3=divers) ergibt die Berechnung einer Standardabweichung oder des Mittelwertes keinen Sinn. Hingegen interessieren einfache Häufigkeiten bei einer Altersvariable (in Jahren) nicht mehr. Hier sind Mittelwert und Standardabweichung entscheidender.
In der Praxis interessieren aber niemanden alle fünf Skalenniveaus. Sondern lediglich die drei: Nominal, Ordinal und Metrisch.
Wichtig! Likert Skalen können aufgrund der gleichgroßen Abstände als quasimetrisch oder pseudometrisch betrachtet werden.
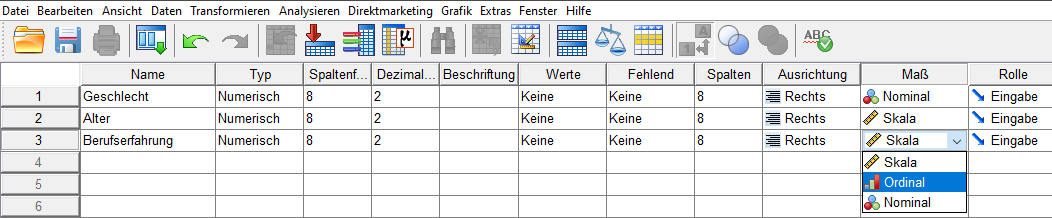
Verschiedene Programme/Programmiersprachen bieten zur Einstellung des Skalenniveaus verschiedene, jedoch sehr ähnliche Möglichkeiten an.
In SPSS findest du es unter Variablenansicht.
In R bzw. RStudio musst du deine Daten mit Funktionen bestimmen.