

Fragebogen auswerten in 3 einfachen Schritten
In vielen natur-, wirtschafts- und sozialwissenschaftlichen Bereichen ist die Befragung das Mittel der Wahl für das Testen empirischer Hypothesen. In diesen einfachen 3 Schritten erklären wir die, wie du vorgehen kannst:
- - Daten aufbereiten
- Daten deskriptiv darstellen
- Daten inferenzstatistisch prüfen
Schritt 1 Daten aufbereiten (70%)
Dieser Schritt stellt die umfangreichste Arbeit dar und macht ca. 70% der gesamten Analyse aus. Zur Datenaufbereitung zählen:
Datenbereinigung (löschen überflüssiger Variablen) Bestimmung der Skalenniveaus, labeln der Variablen und Werte Fehlende Werte löschen oder ersetzen (z.B. durch eine Mittelwertimputation) Überprüfung der Daten auf Plausibilität (stimmen die Daten?), Validität (stellen die Daten dar, was ich messen will?) und Reliabilität (Sind die Konstrukte messgenau?). In der Regel werden etablierte Messinstrumente verwendet, weshalb eine Validierung nicht notwendig ist. Soll ein eignes Messinstrument verwendet werden, müssen aufwändige Faktoranalysen (explorative, konfirmatorische) durchgeführt werden Erstellung der Konstrukte und Datentransformation (Recodierung negativ gepolter Items), dabei kann man sich in der Regel nach dem Manual der Originalstudien der Messinstrumente richten. Für viele Modelle müssen zusätzlich Dummy Variablen erstellt werden Sortieren des Datensatzes. Datenanalyse lebt von Übersichtlichkeit!
Schritt 2 Daten deskriptiv darstellen (10%)
Je nach Skalenniveau werden die Daten nun dargestellt. Für nominale Daten werden Häufigkeiten und Balkendiagramme abgebildet. Dasselbe erfolgt für ordinale Daten, nur kann hier der Median ergänzt werden. Metrische und quasi-metrische Daten werden mit allen Parametern von Verteilungen beschrieben (Mittelwert, Standardabweichung, Median…) Metrische- und quasi-metrische Daten werden mit Boxplots und Histogrammen abgebildet. Zudem werden sie auf Normalverteilung überprüft.
Schritt 3 Daten inferenzstatistisch prüfen (20%)
Dieser Schritt verursacht wohl die meisten Probleme. In Abhängigkeit der Hypothesen, des Skalenniveaus und der Verteilung der Daten muss der richtige Test auf Signifikanz gewählt werden. Zusätzlich muss daraus die Effektstärke berechnet werden. Ergänzend kann auch bayesianische Statistik erfolgen.
Hier beschreiben wir ausführlich, wie man den richtigen Test finden kann
https://www.hanseatic-statistics.de/statistische-tests/testuebersichtHast du Fragen oder brauchst du Hilfe? Kontaktiere uns
https://www.hanseatic-statistics.de/kostenloses-erstgepraechIm Folgenden siehst du Beispiele für Fragebogenauswertung in SPSS und R, jedoch können wir dich auch in JAMOVI, JASP, STATA und Python unterstützen:
Fragebogen Auswertung
Hier siehst du einen Überblick, bei welchen Fragebogen Auswertungen wir dich unterstützen können:
Fragebogen Auswertung in SPSS
Import der Daten
Zuerst musst du die Daten importieren. Viele Umfragetools bieten bereits das SPSS .sps Format an. Einfach geht es auch mit Excel. Eine .xlsx Datei kannst du einfach über Datei🡪öffnen🡪Daten einlesen. Wichtig! Du musst den Datentyp ändern in Alle Formate.
Optional kannst du auch .csv Daten einlesen. Hier musst du jedoch überprüfen, mit welchen Sonderzeichen Variablen und Werte getrennt sind. SPSS bietet dir eine Vorschau an.
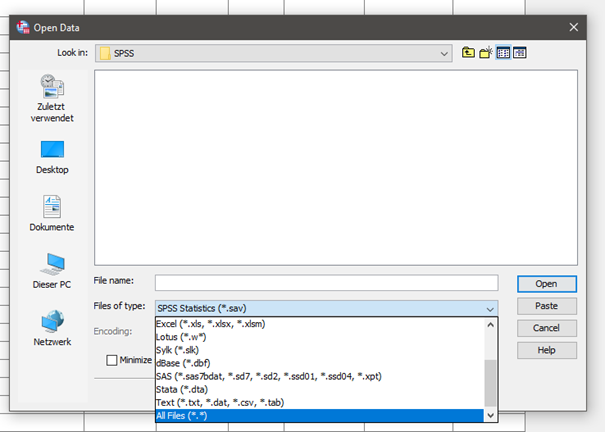
Datenaufbereitung
In SPSS stellt die Datenanasicht nun eine einfache zweidimensionale Übersicht deiner Daten dar. Zeilen sind Versuchspersonen und Spalten Variablen. Unter Variablenansicht kannst du die Variablen bearbeiten.
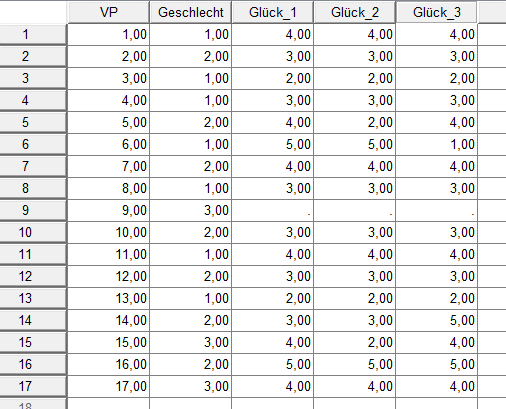
Überflüssige Variablen Löschen
Datenanalyse lebt von Übersichtlichkeit. Lösche also was du nicht brauchst, z.B. Browserdaten, Time Tracker, Indexvariablen etc...
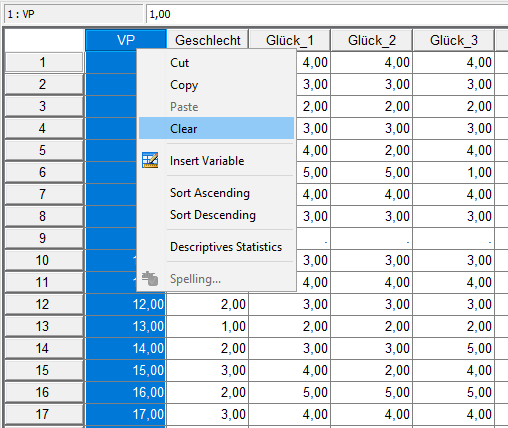
Versuchspersonen filtern
Lösche die Versuchspersonen, die den Fragebogen abgebrochen oder gar nicht ausgefüllt haben.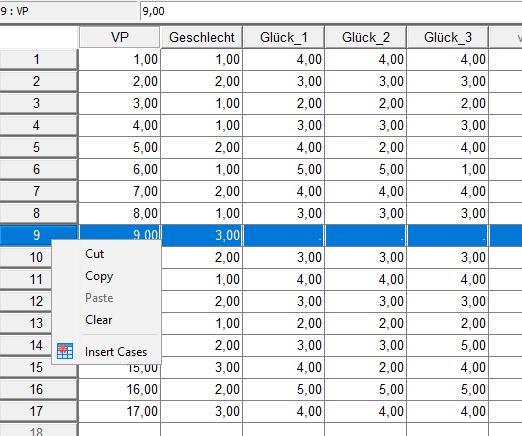
Variablen labeln und beschriften
Beschrifte die Variablen, damit die Grafiken richtig beschriftet und die Häufigkeitstabellen übersichtlicher sind.
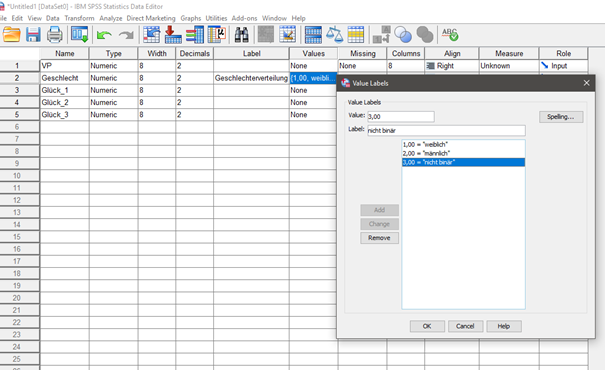
Fehlende Werte löschen oder ersetzen
Was machst du mit einzelnen fehlenden Werten? Man kann hier die gesamte Versuchsperson entfernen oder fehlende Werte ersetzten, z.B. durch eine Mittelwert Imputation.Skalenniveaus anpassen
Skalenniveaus stellen ein sehr wichtiges Thema dar. Von Ihnen hängt ab, was du mit deinen Daten machen kannst. Bestimme also, ob es nominale, ordinale oder metrische Daten sind.
Zu den Skalenniveaus
Reliabilitätsanalyse
Üblicherweise werden Konstrukte durch mehrere Items operationalisiert. Damit dies jedoch funktioniert, solltest du einmal die Reliabilität überprüfen. Hier kannst du Cronbachs-Alpha oder McDonalds-Omega bestimmen.Skalen erstellen
Ist deine Skala reliabel, kannst du die Items zu einem Score zusammenfassen. Dabei wird häufig der Mittelwert gewählt.Deskriptive Statistik
Im ersten Schritt musst du deine Daten nun einmal beschrieben. Hier spielt das Skalenniveau wieder eine entscheidende Rolle, denn von diesem ist der Informationsgehalt deiner Daten abhängig. Dieser entscheidet, was du mit den Daten machen kannst. Einen Mittelwert der Variable, die das Geschlecht einer Person angibt, zu berechnen, ergibt keinen Sinn. Genau so wenig wie einfach Häufigkeiten einer Variablen anzugeben, die das Alter in Jahren misst. Am besten gehst du wie folgt vor:Häufigkeiten für nominale und ordinale Daten
Mediane für ordinale Daten
Statistische Kennwerte und Test auf Normalverteilung für metrische Daten
Inferenzstatistik
Nun folgen die finalen Tests deiner HypothesenDen richtigen Test finden.
Hier spielen nun deine Hypothesen und die Skalenniveaus eine entscheidende Rolle. In unserer Testübersicht kannst du dir einen Überblick verschaffen.
Zur TestübersichtIm Hinblick auf Hypothesen durchführen
Hier kannst du dir einen Überblick über die verschiedenen Arten der Hypothesentests verschaffen, wie Signifikanzwerte, Effektstärke oder Bayes-Statistiken.
Zu den Hypothesentests